Clean Code Remark
Clean Code es muy importante, de hecho, esto pude ser la diferencia entre el exito o fracaso de una empresa.
Todo comienza con las personas y las especificaciones. En un mundo ideal, obtenemos especificaciones completas y detalladas del problema que planeamos resolver con nuestro código. Diseñamos la arquitectura de software del proyecto con el nivel de detalle adecuado. Luego, un equipo de desarrolladores puede comenzar a trabajar e implementar el proyecto. El único problema en este caso: no vivimos en un mundo ideal.
Las especificaciones nunca están completas, incluso con el mejor esfuerzo e intenciones. Siempre habrá detalles en los que nadie pensó. La gente cambiará de opinión. La gente solicitará funciones adicionales. Como resultado, pueden surgir nuevas especificaciones en cualquier momento: en la fase de especificaciones, diseño de software, implementación, despliegue o mantenimiento.
En el libro, se narra la historia de la “Empresa asesinada por el código”. En 1988, una compañía desarrolló un sistema de administración de redes en el lenguaje de programación C. La empresa adquirió un debugger de una empresa llamada Sword, esta herramienta era muy poderosa. Pero dos años más tarde se quiso migrar ese sistema de C a C++, se solicitó el soporte de C++ a Sword, pero tardo mucho en llegar. Finalmente, el soporte de Sword para C++ llegó, el inconveniente fue que uno de sus principales procesos tardaba casi 45 min en cargar y había errores. Se solicitó el nuevo soporte a Sword y aseguraron que lo arreglarían en la siguiente versión. Nuevamente, hubo errores en el depurador. Luego de eso, cancelaron la licencia. Luego de unos meses de la segunda versión, Sword se hundió y su producto desapareció. Esto se debió a que la Sword no supo administrar su código de la mejor manera y con el cambio a C++ simplemente fue una tarea imposible. Se trabajó incansablemente, pero fallaron. En sus palabras:
No podíamos hacer que ese lío enredado de código analizara C++
En otras palabras, Sword Inc. fue destruida por su propio código.
Este es un caso de mala administración de código fuente de un proyecto y uno de los principales inconvenientes que tienen las empresas hoy en día, Clean Code intenta dar una guía para evitar inconvenientes que puedan llevar a casos como el expuesto anteriormente.
La trampa de la productividad
Esto sucede siempre en los proyectos, comienzan rápido, pero luego de algunas semanas o meses el proceso se hace lento. ¿Por qué?, simplemente porque hay un desorden en el código. Con nuevas características o cambios lo que al principio tomaba días, ahora puede tomar semanas, incluso meses. Desde la vista de los administradores o project managers, esto es un inexplicable retraso. El mal código da a pensar que los desarrolladores no trabajan lo suficiente, sin embargo, lo hacen. El verdadero problema es que el código los retrasa. Se podría pensar que si se contrata más programadores significaría el doble de velocidad. Sin embargo, existe algo llamado la ley de Brooks.
Agregar mano de obra a un proyecto de software en retraso, lo retrasará más
Básicamente, agregar más personas implica tiempo de enseñanza y aprendizaje, y si el código está mal desde un inicio, lo seguirá estando cuando las nuevas personas trabajen en él. Todos esperan incrementar la productividad, pero lo único que se incrementa es el desorden.
El gran rediseño en el cielo
Comenzar de nuevo, rediseñar todo, etc. Esta idea emociona a los desarrolladores, pero aterra a los administradores. Ellos quieren saberlo todo en términos de dinero y tiempo. Y además, ¿cómo estarán seguros de que este rediseño arreglará el problema?. El gran dilema es que simplemente hay ocasiones donde no hay otra elección que el rediseño y posiblemente sea la única opción.
Pero hay otro factor importante, los desarrolladores y no deben subestimarlos. ¡Ellos conocen lo que sucede en realidad, los administrativos quizá no! El hecho de volver a rediseñarlo todo, no significa que los problemas se resolverán o que ya no habrá desorden o que la productividad aumentará.
Este rediseño implica que no todos los desarrolladores se dedicarán por completo a este nuevo diseño, ya que algunos aún deben mantener el antiguo sistema, simplemente porque los clientes no pueden esperar meses o años para ver mejoras o que se hayan reparado los problemas.
En algunos casos, en una situación desesperada, los administrativos deciden reemplazar todos los antiguos sistemas por unos nuevos, incluso si estos nuevos sistemas no hacen todo lo que los viejos sistemas hacían.
En conclusión, el gran rediseño es una estrategia que casi siempre falla. Esta solución puede funcionar en cosas pequeñas, pero con grandes proyectos, esto siempre termina en desastre. Y así, el mal código puede destruir un equipo, una división e incluso una empresa.
La decadencia del código
¿Que sucede con el software con el tiempo?, ¿Por qué cae en decadencia?
Al comienzo, el diseño es usualmente simple, elegante y hermoso. De igual manera, cuando escribimos las primeras líneas de código, es simple, fácil de cambiar y elegante. Pero con el tiempo el código empieza a decaer.
La decadencia del código ocurre con mayor frecuencia cuando los desarrolladores realizan tareas de desarrollo de software en una base de código existente. En un proyecto desordenado, agregar nuevas funciones se vuelve cada vez más difícil y crea aún más desorden. Los desarrolladores pueden elegir el enfoque rápido y desordenado o el lento y limpio.
¿Qué hace que el código caiga en decadencia?
- Rigidez: Es la tendencia de un sistema a resistir cambios. Un sistema es rígido cuando se tienen que hacer varios cambios en diferentes lugares para resolver un problema simple o agregar un nuevo comportamiento. Una de las cosas más frustrantes en un sistema rígido es que son impredecibles. Por ejemplo, no es posible estimar el tiempo en resolver un problema o agregar una característica porque no se conoce cuantos módulos hay que cambiar.
- Fragilidad: Un sistema es frágil cuando el reparar un simple bug o agregar una nueva característica causa un mal funcionamiento en una o muchas partes del sistema, incluso si no están conectadas con la parte donde se ha hecho el cambio.
- Inseparabilidad: Un sistema es inseparable cuando las partes que en verdad pueden ser usadas en otro sistema no pueden ser separadas de dicho sistema. En otras palabras, las partes de un sistema no pueden funcionar de manera independiente o no pueden ser usadas en otros sistemas.
- Opacidad: Opacidad es la tendencia de un sistema a ser mal estructurado. En otras palabras, cuando leemos el código, este dice poco o nada sobre lo que hace o como trabaja. Es difícil de leer, cambiar o entender.
¿Por qué el código cae en decadencia?
La decadencia del código es un proceso en el que incluso un proyecto bien diseñado y bien escrito se vuelve desordenado e imposible de mantener con el tiempo. En pocas palabras, los mismos desarrolladores hacen que el código caiga en decadencia. Muchas veces debido a la premura que requiere el proyecto o el cliente. Y muchas veces pensamos mal en querer arreglar el código cuando no hay prisa, pero en realidad esto nunca sucede. Ya sea porque el proyecto crece o porque los horarios nunca dan ese tiempo para dichas reparaciones. La ironía es que, por mucho desorden que se haga, esto no ayuda a ser más rápidos, por el contrario, retarda el desarrollo.
La única manera de ir rápido, es hacerlo bien
¿Qué es clean code?
Me gusta que mi código sea elegante y eficiente | Clean code debe hacer una cosa. Bjarme Stroustrup (creador de C++)
- Un código elegante es un código que hace mucho en pocas palabras.
- Un código eficiente usa muy pocos ciclos de CPU en una tarea
Un código limpio es simple y directo. Grady Booch
El còdigo limpio siempre se ve como si estuviera escrito por alguien a quien le importa. Michael Feathers
Sabes que estas leyendo un código limpio cuando cada rutina que lees es mas o menos lo que esperabas. Ward Cunningham
Características de Clean Code
- Elegante y eficiente
- Expresivo
- Sencillo
- Manejo de errores
- Legible (pasamos más tiempo leyendo código que escribiendo código)
- Fácil de modificar
- Posee pruebas automáticas
- Hecho por alguien que le importa
- Sin duplicidad
La regla del niño explorador
Deja al mundo mejor del que encontraste | Deja el código más limpio de como lo encontraste
¿Qué pasaría si dejamos nuestro código mejor del que encontramos?, simplemente nuestro código mejoraría todo el tiempo.
Names++
Los nombres están presentes en todo el software: directorios, archivos, clases, métodos, variables, namespaces. Probablemente, deberíamos saber como nombrar todo esto de manera correcta. Cada vez que escoges un nombre, este debería revelar la intención de lo que intentas nombrar. Si necesitas un comentario para ayudarte con esto, probablemente este nombre no sea el adecuado. Se solía agregar un comentario junto a las variables para expresar su significado. Pero es mucho mejor que el nombre de la variable se describa a sí misma y este nombre actúe como su propio comentario.
Es importante que nuestro código forme una especie de comentario compilable que explique la intención del autor.
Antes se consideraba mucho el rendimiento del programa en términos de ciclos de reloj y memoria. Pero esas preocupaciones no deberían ser muy tomadas en cuenta cuando entendemos que el verdadero costo del software es el mantenimiento del mismo, incluso si esto implica un par de ciclos de reloj y bytes de memoria.
Describe el problema
Los nombres que describen los detalles de implementación, no revelan la intención. Ellos hablan más del problema que se quiere resolver. Si debes leer el código para comprender un nombre, el nombre prácticamente no se expresa a sí mismo y se considera un mal nombre. Hay que recordar que la primera intención en un nombre es comunicar su significado (esa siempre es la primera prioridad). Esto es incluso más importante que asegurarse de que el código funcione.
Siempre elige nombres que comuniquen lo que quieres hacer
Evita la desinformación
¡Si has visto nombres en un código que no sabes lo que significa… eso es desinformación! Y usar estas malas prácticas es una de las peores maneras de programar. ¡Los nombres simplemente no describen el comportamiento del código!
La conclusión es que el nombre debe decir que significa y significa exactamente lo que dice
Hay que tener en cuenta que en ocasiones es difícil cambiar los nombres de las variables, métodos, clases etc. O incluso en una API de terceros, los nombres ya están definidos. Y en ocasiones esto puede tomar mucho tiempo de entender. Pero a pesar de eso, es importante recordar que nuestros nombres no deben tener desinformación.
Nombres pronunciables
Es importante dar a nuestros nombres una semántica y que sean pronunciables. Por ejemplo la pariable PC_GWDA . Esta variable no tiene una clara pronunciación. No es correcto hacer esto a los lectores de nuestro código. En muchas de las ocasiones los nombres son convenientes para los autores, pero.. ¿qué hay sobre los lectores?
Los nombres no deben ser elegidos a nuestra conveniencia. Deben ser consideradas como herramientas que usamos para comunicarnos.
Evite las codificaciones
Un ejemplo claro es la notación húngara. Esta consistía en agregar al nombre de la variable el tipo de dato que esta contenía. Pero este tipo de notaciones hoy en día resultan irrelevantes ya que nuestros editores nos ayudan a detectar el tipo de una variable. Existen notaciones que siguen usandose como incluir una C para identificar una clase o una I para identificar una interfaz. Este tipo de notaciones tienden a obscurecer el significado y calidad del código, ya qu elo vuelven más complejo de leer.
Simplemente usa nombres claros y pronunciables y deja que tu editor cumpla su trabajo de identificar el tipo de dato o si es clase o interface etc.
Partes de la oración
Siempre se ha dicho que los nombres que corresponden a clases o variables son sustantivos, mientras que los nombres de los métodos son verbos. El nombre de una clase o variable siempre debe ser un sustantivo o una frase nominal. Las variables siempre se usan para instancias de clases, entonces, deben ser sustantivos también. Las variables booleanas deben ser escritas como predicados por ejemplo: isEmpty o isDone. Los métodos deben ser verbos o frases verbales. Las enumeraciones tienden a ser estados o descripciones de objetos por ende deben ser adjetivos.
La regla de la longitud del alcance
Esta regla nos habla sobre el alcance que tienen las variables. Si el alcance de una variable es pequeño o se usa en pocas líneas es muy correcto simplificar su nombre o usar nombres cortos, ya que es mucho más sencillo leer y entender el código de esta manera.
Esta es una de las reglas más intersantes sobre los nombres, existe una estrecha relación entre el alcance y la longitud del nombre. Si se tiene un alcance bastante amplio la el nombre debe ser lo más claro posible. En el caso de las funciones y las clases, siguen la regla opuesta: Cuanto más amplio sea el alcance, más corto debe ser el nombre de la función o clase.
Las funciones públicas tienen grandes alcances, son llamadas desde diferentes lugares del código; por ello se les debe dar nombres cortos y precisos. Este mismo argumento se usa para nombres de clases, especialmente clases públicas. Las clases públicas tienen un gran alcance; probablemente deberían tener nombres cortos y convenientes. Por otro lado las clases privadas tienen alcances más reducidos y posiblemente necesiten de nombres más largos que expresen aún más su significado.
Cualquier tonto puede escribir código que una coputadora pueda entender, pero un buen programador es capaz de escribir código que un humano pueda entender.
Functions
Sabemos que una función es una pieza de código reutilizable por lo que hay que tener en consideración lo siguiente:
Una función debe ser pequeña
(Es decir debe tenerse en cuenta las líneas de código, sin embargo no hay métricas definidas sobre esto). De esta manera se puede entender fácilmente que es lo que hace, brinda oportunidades de mejora y una mejor lectura. En este punto un proceso iterativo es recomendable, ya que a la primera es difícil escribir la mejor función, sin embargo con un proceso de mejora contínua se pueden lograr esos resultados.
Regla de identación
Se recomienda que nuestras funciones no deben tener más de dos niveles de identación, pero llegar a 5 6 7 niveles puede darse el caso de que una función este mal diseñada. Muchos niveles de identación hacen que modificar y entender el código sea muy difícil.
Las funciones deben hacer solamente una cosa (y debe hacerla bien)
Se deben hacer tareas específicas acorde al nombre de la función.
Uso de switch
Se recomienda usar lo menos posible estas estructuras pueden generar mucho código repetido. Varias funciones pueden usar estas estructuras con la misma lógica, esto hace que a largo plazo el mantenimiento sea más difícil.
Nombres descriptivos (verbos y keywords)
Hay que recordar que los nombres de las funciones deben ser expresados por verbos, pero también se recomienda agregar un keyword que nos permite darle un mejor contexto a la función. Habrá ocasiones en las que el contexto será suficiente para entender una función y un keyword no sea tan necesario. En contextos más generales puede valer la pena agregar esa palabra clave que nos ayude a entender lo que hace una función.
export class RepositorioPersonas { agregar() {} agregarPersona() {} }
Argumentos
Se recomienda que la mayoría de funciones tenga cero argumentos ya que son funciones más fáciles de entender. Entre más argumentos existan más se dificulta entender una función.
- Las funciones con un argumento deben ser utilizadas en tres casos: pregunta, transformación, evento.
bool existe = File.Exists(path); FileStream fileStream = File.OpenRead(path); EmitirAlertaExitosa('Message sended');
- Las funciones con dos argumentos pueden causar confusiones en cuando al envío de parámetros (el orden es importante). Estos problemas se pueden mitigar usando nombres para los parámetros.
- Si se tienen más de 3 o 4 argumentos es mejor encapsularlos en un objeto para mejor la legibilidad.
Efectos secundarios
Evitar lograr más de una acción en la función. Cuando invoco la función no estoy consiente que aparte de virificar la existencia hay otras acciones. Podría solventarse acalarando el nombre de la función.
Excepciones, no status
Las funciones deberían arrojar un error cuando el comportamiento no es el esperado. Por ejemplo si invoco a una función para verificar la existencia de un producto, esperaría que la función devuelva verdadero o falso. Pero no es recomendable hacer que la función retorne un valor por ejemplo indicando que el producto no fue encontrado. Es mejor usar excepciones o estructuras try-catch.
Manejo de errores
Al monento de usar las excepciones se debe tener en cuenta la forma de usar las estructuras try-catch e incluir nuestra función de la mejor manera.
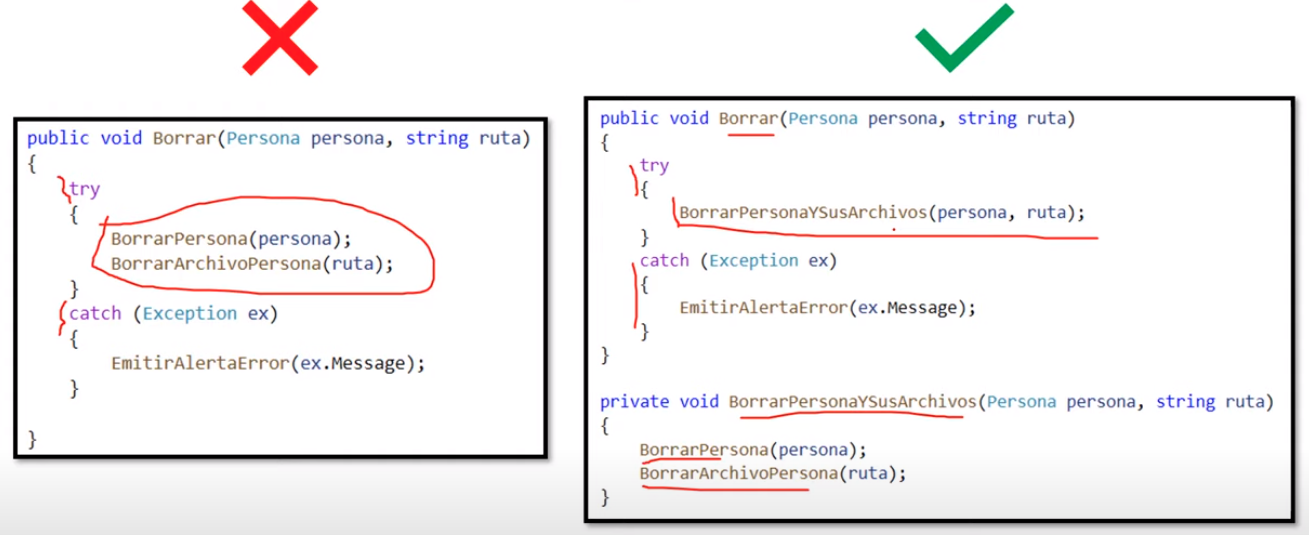
NO repetir código
Crea funciones de manera que centralices tu funcionalidad en un solo lugar, y no tengas que repetir código en varios lugares. Habrá ocasiones en las que es fàcil centralizar el código y otras que es muy dificil o no vale la pena.
Test driven development
Si hablamos de TDD sabemos que el código cae en decadencia porque nos asusta la idea de limpiar nuestro código y la única manera y de eliminar ese miedo es un conjunto completo de pruebas. Sabemos que TDD nos provee una forma segura de generar un conjunto de pruebas confiables. Las tres leyes de TDD:
- No puede escribir ningún código de producción hasta que primero escriba una prueba unitaria fallida.
- No puede escribir más de una prueba unitaria de lo suficiente para fallar, y no compilar es fallar.
- No puede escribir más código de producción del suficiente para pasar la prueba que falla actualmente.
Seguir estas tres leyes, podrá reducir el tiempo de depuración, generar documentación confiable de bajo nivel, desacoplar su diseño, pero sobre todo, eliminará el miedo al cambio. Y eso significa que puedes limpiar tu código.
Architecture, use cases and high level design
La arquitectura se encarga de sentar las bases de todo un sistema de software. Está compuesto por decisiones del más alto nivel, decisiones que deben tomarse primero. Decisiones que deben sobrevivir a la vida útil del software.
Los programadores son todos arquitectos, de una forma u otra, y que los arquitectos que no codifican no son arquitectos en absoluto.
La arquitectura es la forma que toma el sistema para cumplir con sus casos de uso y para permanecer flexible y mantenible. La arquitectura de un sistema es el conjunto de decisiones tempranas e irrevocables que sientan las bases de todo el sistema y su desarrollo. Cuando elegimos las tecnologías que un sistema usará no estamos hablando de arquitectura (esas no son desiciones arquitectónicas)
La arquitectura no se trata de las herramientas sino, más bien tiene que ver con el uso.
Una buena arquitectura, tiene que ver con cómo se utiliza el sistema. Una buena arquitectura necesita casos de uso. Cuando observa un sistema de software, y todo lo que puede ver es la estructura Modelo-Vista-Controlador de un sistema web, entonces la arquitectura de ese sistema oculta los casos de uso y expone el mecanismo de entrega. No queremos ver el mecanismo de entrega. Queremos ver los casos de uso.
No queremos que los casos de uso estén acoplados al mecanismo de entrega. Queremos que la separación entre la UI y los casos de uso sea muy sólida. Tan fuerte, de hecho, que pueden desplegarse independientemente uno del otro. No queremos que los casos de uso sepan nada sobre el mecanismo de entrega. De hecho, queremos decisiones sobre la UI, la DB, frameworks y herramientas, capas de servicio, queremos que todas esas decisiones sean completamente independientes de los casos de uso.
Los casos de uso deben estar solos. Las decisiones sobre las DBs, la UI y las capas de servicio pueden y deben posponerse. Uno de los objetivos principales de una buena arquitectura, esque permite posponer decisiones sobre frameworks, servidores web, UI, etc.
Una buena arquitectura maximiza el número de decisiones no tomadas.
¿Cómo se desvincula de las herramientas, los frameworks y las bases de datos? Enfoca tu arquitectura en los casos de uso, no en el entorno de software.
¿Y qué si todo el valor del sistema está realmente en la interfaz de usuario? Un sistema CRUD simple. Si la interfaz de usuario es crítica, no queremos que su arquitectura se vea contaminada por las preocupaciones del resto de la aplicación. Otra forma de ver esto es la separación del valor comercial. Considere por un momento solo los casos de uso y la interfaz de usuario. Digamos que hemos separado estos dos en componentes que se pueden implementar y desarrollar de forma independiente, de modo que la interfaz de usuario es un complemento para los casos de uso.
Separar los casos de uso de la interfaz de usuario permite a la empresa medir el costo de cada uno y luego comparar ese costo con el valor comercial correspondiente. Entonces, al enfocar la arquitectura de nuestra aplicación en sus casos de uso, podemos diferir las decisiones sobre la interfaz de usuario, la base de datos u otros componentes del sistema. Este aplazamiento nos permite mantener nuestras opciones abiertas durante el mayor tiempo posible, y eso significa que podremos cambiar de opinión si es necesario, quizás muchas veces durante el curso del proyecto, sin costo indebido.
Casos de uso
Los casos de uso forman los principios y las abstracciones alrededor de las cuales se construye el sistema, independientemente del mecanismo de entrega. Cuando observa la arquitectura de un sistema basado en casos de uso, ve los casos de uso, no el mecanismo de entrega. Lo que ves es la intención del sistema.
Un caso de uso es nada más y nada menos que una descripción formal de cómo un usuario interactúa con el sistema para lograr un objetivo específico.
Por ejemplo, supongamos que el objetivo era crear un pedido dentro de un sistema de procesamiento de pedidos. Entonces el caso de uso debería hablar de los datos y los comandos que ingresan al sistema, y la forma en que responde el sistema.
El caso de uso es esencialmente un algoritmo para la interpretación de datos de entrada y la generación de datos de salida.
¿Cómo dividimos nuestro sistema de tal manera que estos casos de uso se conviertan en el principio organizador central?
Las buenas arquitecturas se conforman por 3 objetos:
- Objetos comerciales: “entidades”
- Objetos de interfaz de usuario: “boundaries”
- Objetos de casos de uso: “controls” ó “interactors”
Describimos el comportamiento del sistema en términos de casos de uso. Capturamos los comportamientos específicos de la aplicación de esos casos de uso en objetos interactivos. Capturamos el comportamiento agnóstico de la aplicación en objetos de entidad controlados por esos interactuadores. Luego, dejamos la interfaz de usuario a un lado, como un gran apéndice, utilizando objetos que se comunican con los interactuadores.
En una arquitectura que aísla el mecanismo de entrega y la base de datos de los casos de uso de la aplicación. Aplicar TDD sería muy fácil en todo el código de la aplicación. Además permitirá que hacer las pruebas sean relativamente sencillo. Además, todo ese aislamiento hace que esas pruebas se ejecuten muy rápido. Ya que no necesitas la base de datos o un servidor web.
Las arquitecturas bien organizadas te hacen ir más rápido, porque todos saben a dónde va todo.
Una buena arquitectura le permite a la empresa separar el costo de los casos de uso del costo de la interfaz de usuario y otros componentes del sistema, lo que le permite a la empresa comparar ese costo con sus valores comerciales correspondientes. Los casos de uso del sistema deben ser las abstracciones principales y los principios organizativos centrales de la arquitectura del sistema. Que cuando observa esa arquitectura, debe ver la intención del sistema y no la interfaz de usuario.
Muchas empresas establecen un rol técnico de alto nivel al que llaman “Arquitecto”. A veces este papel es más político y administrativo que técnico. Otras empresas promoverán a los programadores y desarrolladores senior al estado de “Arquitecto”. Es posible que no esperen que estos arquitectos codifiquen. En cambio, el rol es una especie de líder técnico de alto nivel, alguien que establecerá la forma de las interfaces y los diseños de alto nivel, tal vez podría llegar a hacer algunas revisiones de código. Si eres un arquitecto y quieres ser efectivo en ese rol, entonces escribes código. Deberías trabajar junto a los programadores para que puedas ver cuáles son los verdaderos problemas arquitectónicos. No tienes que codificar el 100% del tiempo. Ni siquiera tiene que codificar el 50% del tiempo. Pero tienes que codificar parte del tiempo, y cuando codificas, debes codificar bien.
Clean Code es mucho más que un tedioso libro, aunque te parezca un poco viejo y desactualizado, sus conceptos han sido la base de muchas de las buenas prácticas y principios utilizados hoy en día en el desarrollo del software. Es importante poner en práctica estos conceptos y principios para crear código “elegante”, y ser mejores desarrolladores, el emplear estos principios puede hacer la diferencia entre un buen y un mal desarrollador. Y no olvides la regla del niño explorador:
Deja al mundo mejor del que encontraste
You can find this and other posts on my Medium profile some of my projects on my Github or on my LinkedIn profile.
¡Thank you for reading this article!
If you want to ask me any questions, don't hesitate! My inbox will always be open. Whether you have a question or just want to say hello, I will do my best to answer you!